诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文全名:Language Models are Unsupervised Multitask Learners
论文下载地址:https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
官方博文:
Better language models and their implications
GPT-2: 6-month follow-up
GPT-2: 1.5B release
官方GitHub项目:openai/gpt-2: Code for the paper “Language Models are Unsupervised Multitask Learners”
对代码的整理和用代码实现GPT-2的解决方案请参考本文第4章
本文是OpenAI于2019年推出的GPT-2论文,核心思想是用无监督思路构建的语言模型来直接解决NLP问题,做一个通用大模型而非领域专家。
GPT-2本身也是个纯英文的模型。
GPT-1:Re45:读论文 GPT-1 Improving Language Understanding by Generative Pre-Training
GPT-2是因果/单向LM,预训练目标是通过前文预测下一个单词。
huggingface提供的在线试用GPT-2-large的平台:https://transformer.huggingface.co/doc/gpt2-large
打字后按Tab获得提示。

文章目录
1. 研究背景
现在的有监督方法的缺点:有监督模型不鲁棒,只能在IID测试集上表现良好。当前已经开始研究多任务通用模型,但多任务学习表现不好,而且要求高标注量。
现在的预训练方法还需要有监督微调。
2. 模型
语言模型:
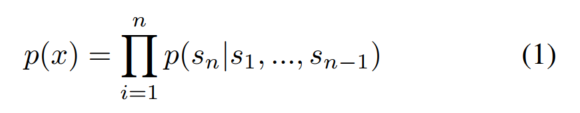
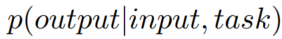
可以用文本生成任务来建模所有NLP任务,这种思路统一了无监督和有监督任务的形式。
不同大小的GPT-2:

- tokenization
Byte Pair Encoding (BPE) 改造版:原始BPE是贪心,这导致重复相似词出现,导致非最优和占空间。本文改为不让它在字节序列之间合并。 - Layer normalization:加到每个sub-block输入,和最后一个self-attention block后
- 词表、上下文长度、batchsize增大
- 学习率是手动调整的,目标使测试集(5% WebText)perplexity最低
- 模型仍未收敛
- 位置向量
绝对位置编码,默认pad到右边。
3. 实验
3.1 数据集
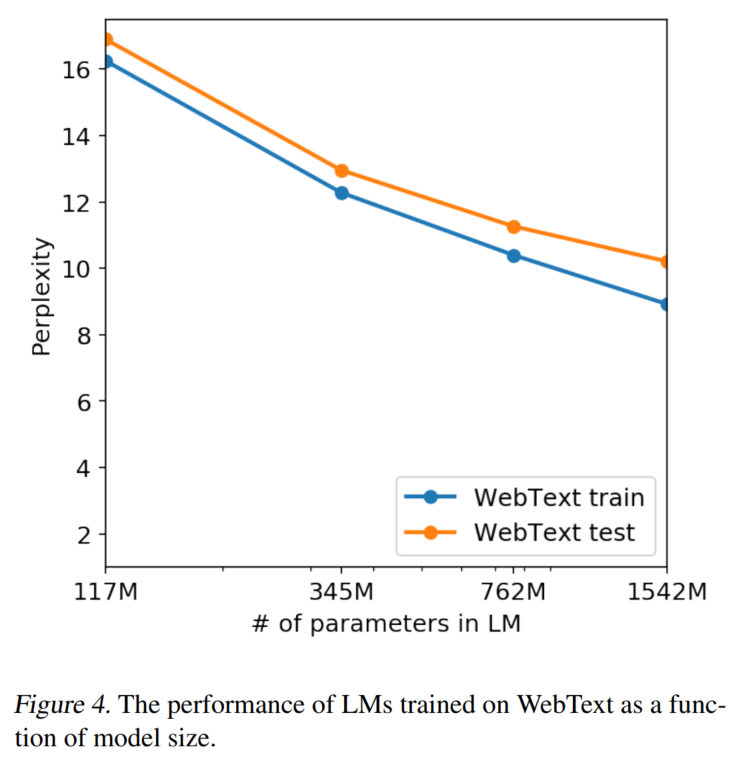
语料:WebText
来源于爬虫
在预训练时删掉了非英语网页(所以翻译效果不好也很正常)
语料中蕴含的翻译知识:

下游多任务:
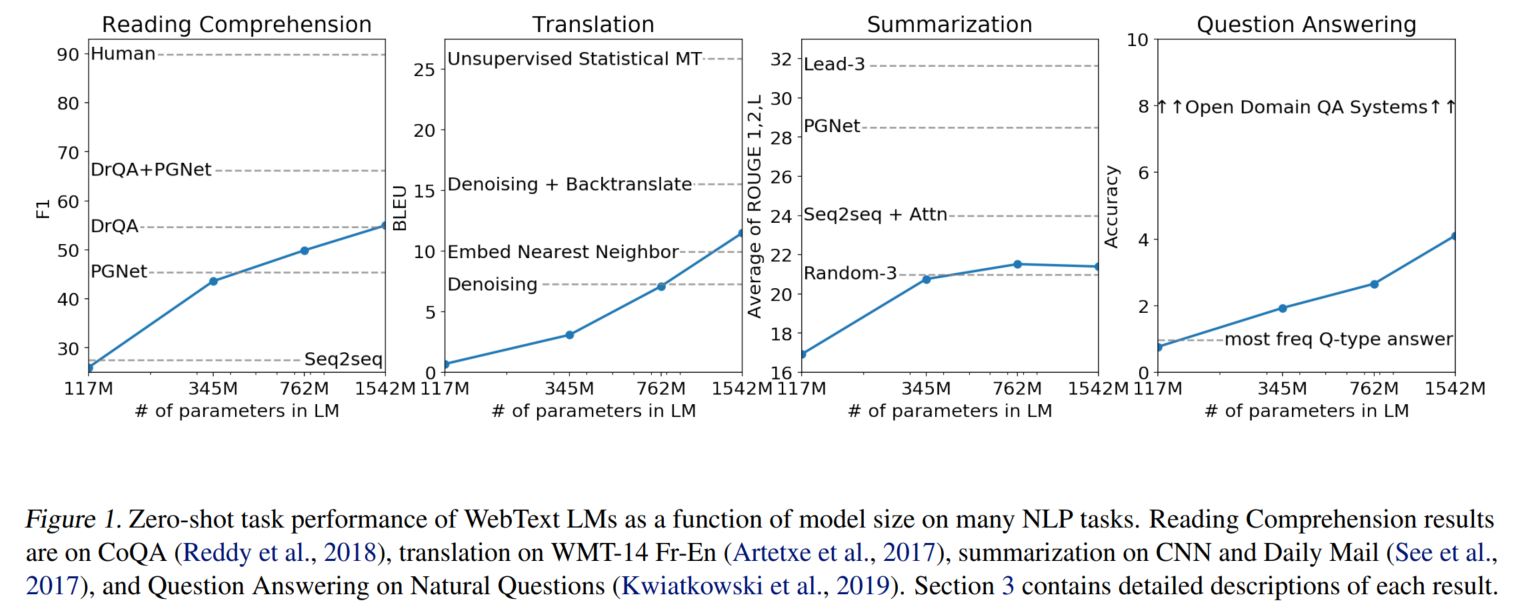
阅读理解:CoQA
翻译:WMT-14 Fr-En
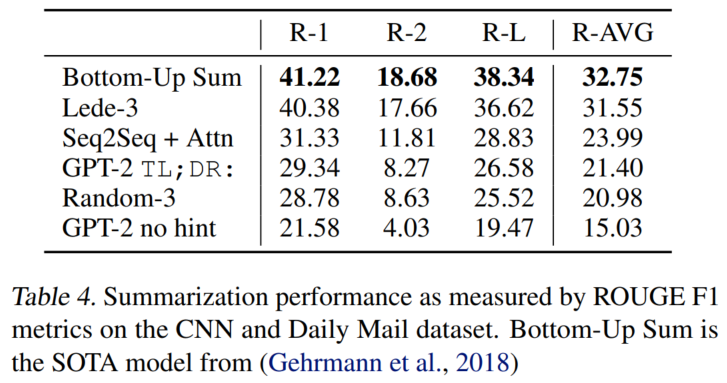
摘要:CNN and Daily Mail
QA:Natural Questions
3.2 实验结果
LM实验结果
基本上都是模型尺寸越大,效果越好。
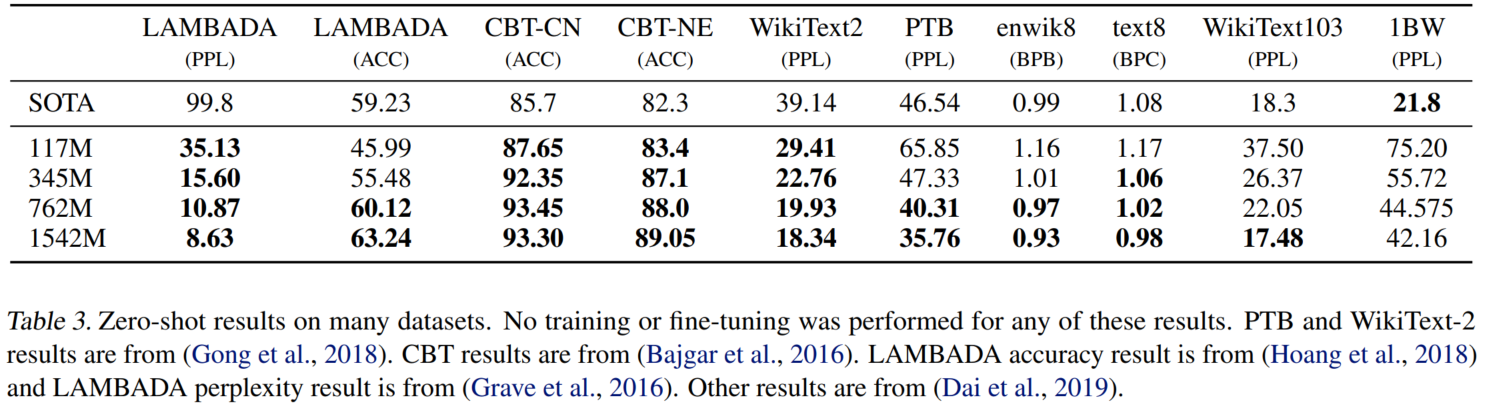
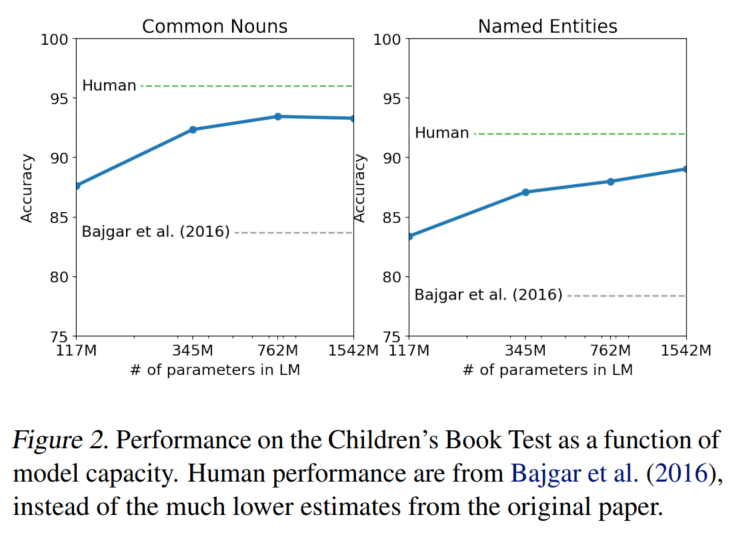
CBT:
LAMBADA
Winograd Schema Challenge:commonsense reasoning

下游任务实验结果
零样本多任务,模型尺寸越大,效果越好:
生成摘要的prompt:TL;DR:
翻译给出少样本上下文(english sentence = french sentence)和prompt(english sentence =)
QA:
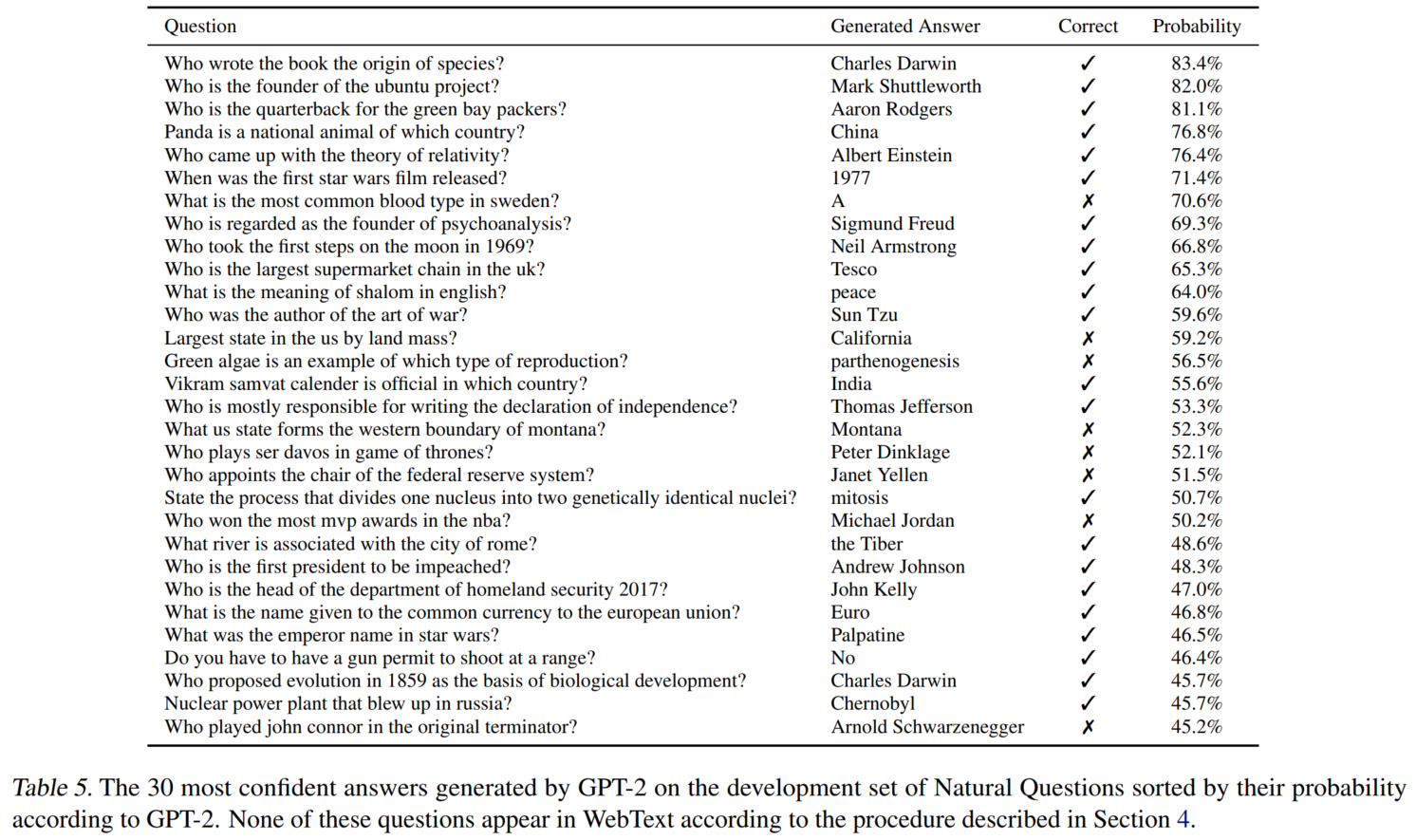
可以看出GPT-2置信度高的样本准确率确实高。
Generalization vs Memorization
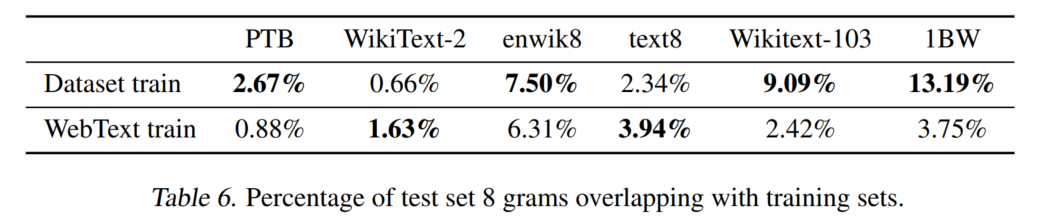
训练集与测试集重复度较低,所以可以认为模型是真的实现了泛化,而不是单纯的记忆。
语料训练集与测试集的重复程度:(第一行是原始数据的训练集,第二行是WebText的训练集)
文字描述的下游数据上的重复率略。
这个是通过8-gram布隆过滤器计算的,具体略。
8-gram覆盖率
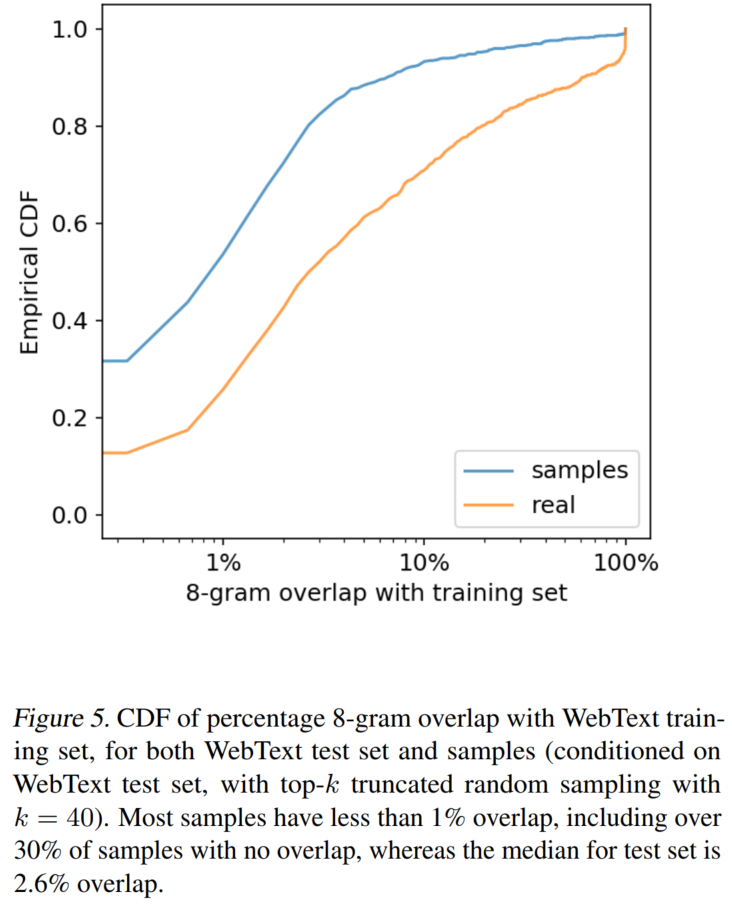
OOD生成样例

更多示例见论文附录和官方博客,我就不列出来了。
4. 复现
4.1 官方代码
官方代码是5年前的TensorFlow 1,想想就知道我不可能会。TensorFlow是不可能学的,这辈子都不可能学TensorFlow的,PyTorch又好用,社区丰富,超喜欢这里的。
BPE tokenize:https://github.com/openai/gpt-2/blob/master/src/encoder.py
建模:https://github.com/openai/gpt-2/blob/master/src/model.py
生成:https://github.com/openai/gpt-2/blob/master/src/sample.py
无条件生成文本:https://github.com/openai/gpt-2/blob/master/src/generate_unconditional_samples.py
有条件(基于prompt)生成文本:https://github.com/openai/gpt-2/blob/master/src/interactive_conditional_samples.py
4.2 基于transformers实现GPT-2
GPT-2是AR语言模型,所以要用语言模型(AutoModelWithLMHead)来实现各项任务。不是seq2seq模型,所以应该不能用seq2seq模型的框架……
不过我也没试过那么干就是了……
官方提供的GPT-2权重(都是纯英文的):
openai-community/gpt2 · Hugging Face:OpenAI官方提供的最小的GPT-2权重
https://huggingface.co/openai-community/gpt2-medium
https://huggingface.co/openai-community/gpt2-large
https://huggingface.co/openai-community/gpt2-xl
https://huggingface.co/distilbert/distilgpt2
4.2.1 基于GPT2LMHeadModel + PyTorch原生框架实现S2S任务微调和推理
数据集构建:https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/GPT2DataSet.py
微调:https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/finetune.py
推理:https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/test.py
关于generate()函数的使用可以参考这篇博文:文本生成解码策略及其在transformers中的代码实现 及配套的代码,展示了不同解码方案输出的效果:https://github.com/PolarisRisingWar/all-notes-in-one/blob/main/decode_examples_in_GPT2.ipynb
4.2.2 基于GPT2LMHeadModel + transformers.Trainer微调GPT-2
参考代码:https://github.com/PolarisRisingWar/Math_Word_Problem_Collection/blob/master/codes/finetune/gpt2/finetune_w_Trainer.py
5. 本文撰写过程中参考的其他网络资料
- OpenAI GPT2
- https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-generation/run_generation.py:这个是transformers的AR语言模型的示例
- Fine-tune a non-English GPT-2 Model with Huggingface:用德语语料训练GPT-2的示例,本文撰写基于Trainer微调时参考了这篇博文的代码
- python - How to build a dataset for language modeling with the datasets library as with the old TextDataset from the transformers library - Stack Overflow:这篇的意义就是跳转到下面这个讨论↓
- Help understanding how to build a dataset for language as with the old TextDataset - 🤗Datasets - Hugging Face Forums
- 图解GPT-2 | The Illustrated GPT-2 (Visualizing Transformer Language Models)-CSDN博客:这篇具体介绍了GPT-2原理
我之前写的Transformer和GPT-1的博文其实也有涵盖,但是没有这篇这么有针对性。而且这篇对attention的介绍与我写的理解角度不同,可资参考。补充的点在于 ① 最后一个block输出与embedding相乘得到logits,对这个logits进行采样得到预测token ② GPT-2一般用top-k=40 - 图解自注意力机制_masked self-attention-CSDN博客:上文中的自注意力部分独立成章
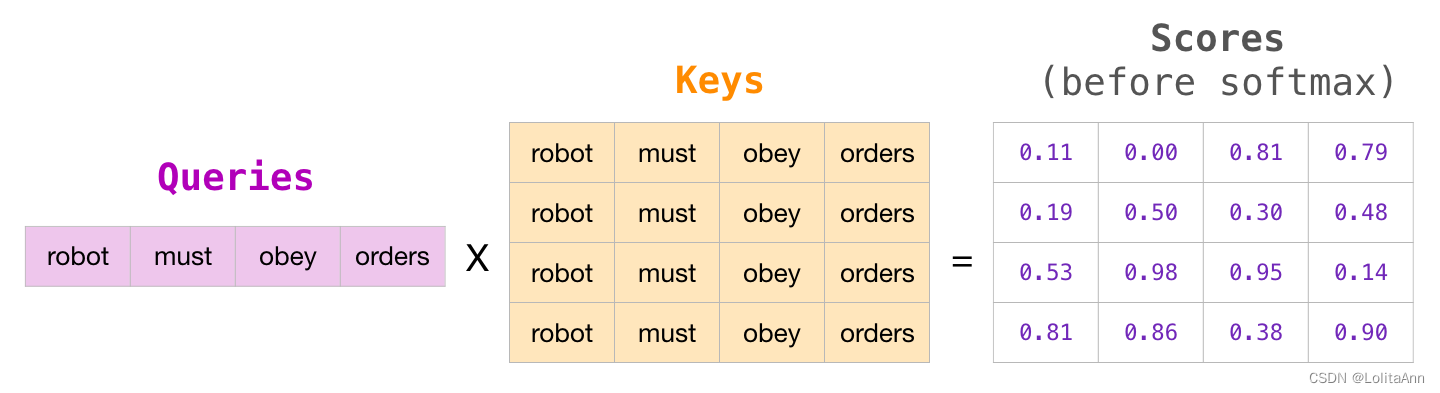
这个masked attention图画得挺到位的,带了数字而且颜色更好看:


这篇补充多头注意力机制peojection过程是不改变维度的 - https://github.com/huggingface/transformers/blob/870ff9e1dab249e4ffd8363ce132aa5145c94604/src/transformers/models/gpt2/modeling_gpt2.py:transformers官方实现
代码集成性太高了,一下子看不懂,以后有时间慢慢研究吧 - GPT-2 论文+代码笔记 | Yam:这篇对论文做了解读,同时对GPT-2原代码做了解读,内容很全面。
用Conv1d做线性转换这事真奇怪啊…… - GPT-2代码解读[2]:Attention_gpt attention qpv-CSDN博客:这篇主要的特色是对GPT-2原代码中attention部分进行解读
↑虽然但是,我也不用TF 1……总之是值得在需要时进一步了解的。但是,有没有PyTorch实现更简洁的解读啊 - Training CodeParrot 🦜 from Scratch:这篇博文涵盖了更多大模型训练技巧,包括对多卡的处理。由于我暂时用不到所以没细看,如果有需要可以看看。