【Langchain Agent研究】SalesGPT项目介绍(三)-CSDN博客
github地址:GitHub - jerry1900/SalesGPT: Context-aware AI Sales Agent to automate sales outreach.
上节课,我们主要介绍了SalesGPT的类属性和它最重要的类方法from_llm()。因为SalesGPT没有构造器方法,所以类方法from_llm()方法就是这个类的构造方法,所以这个类方法很重要。
第二节课的时候我们讲过(【Langchain Agent研究】SalesGPT项目介绍(二)-CSDN博客),这个项目的运行代码是run.py,但是在我仔细研究项目的逻辑后发现,run.py的代码是有很明显的逻辑错误的,应该压根就跑不起来、或者会进死循环的,所以没有办法,我自己写了一个test方法来把这个项目跑起来,然后我把运行过程拆开,方便我们用debug来看一下代码运行过程中的中间变量。在介绍我们自己的test方法的过程中,我会顺便介绍SalesGPT其他几个重要的方法 step(), human_step(),_call(),determine_conversation_stage(),基本上掌握了这些方法就能够运行整个项目了。
run.py运行代码有逻辑问题
首先跟大家说一下,我仔细研究了项目自带的run.py方法,感觉不太对头,就是它的这个方法里少了关键的调用determine_conversation_stage()方法,我们来看一下:
sales_agent.seed_agent()
print("=" * 10)
cnt = 0
while cnt != max_num_turns:
cnt += 1
if cnt == max_num_turns:
print("Maximum number of turns reached - ending the conversation.")
break
sales_agent.step()
# end conversation
if "<END_OF_CALL>" in sales_agent.conversation_history[-1]:
print("Sales Agent determined it is time to end the conversation.")
break
human_input = input("Your response: ")
sales_agent.human_step(human_input)
print("=" * 10)这块代码之前没有啥问题,但是在seed_agent()之后,从来没有调用过determine_conversation_stage()这个方法,这个在逻辑上是不对的,我们回忆一下我们第一课上讲的东西,整个业务逻辑是这样的:

注意在用户输入之后、在Agent响应之前,每次都是要做阶段判断的,如果不判断对话阶段,是根本无法正确地和用户交互的,相当于整个逻辑链少了一个关键环节,这是一个很明显的错误,希望大家也能发现这个问题。
我们自己构造一个运行程序my_test.py
我们自己尝试构造一个运行程序,去把这个项目跑起来,因为有很多问题只有把代码跑起来才能发现其中的问题:
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from salesgpt.agents import SalesGPT
load_dotenv()
print(os.getenv("OPENAI_API_KEY"))
llm = ChatOpenAI(
temperature=0,
openai_api_key = os.getenv("OPENAI_API_KEY"),
base_url = os.getenv("OPENAI_BASE_URL")
)这里注意一下,我对项目用的ChatLiteLLM不太熟悉,不知道他怎么设置base_url的,因为我用的是国内openai节点,所以我索性不用ChatLiteLLM了,我直接用咱们以前项目用过的ChatOpenAI包装器,方便我修改base_url。
sales_agent = SalesGPT.from_llm(
llm,
verbose=True,
use_tools=False,
salesperson_name="Ted Lasso",
salesperson_role="Sales Representative",
company_name="Sleep Haven",
company_business="""Sleep Haven
is a premium mattress company that provides
customers with the most comfortable and
supportive sleeping experience possible.
We offer a range of high-quality mattresses,
pillows, and bedding accessories
that are designed to meet the unique
needs of our customers.""",
)
sales_agent.seed_agent()
sales_agent.determine_conversation_stage()到这里,我们要注意一下,由于我换了模型,直接运行会报错:
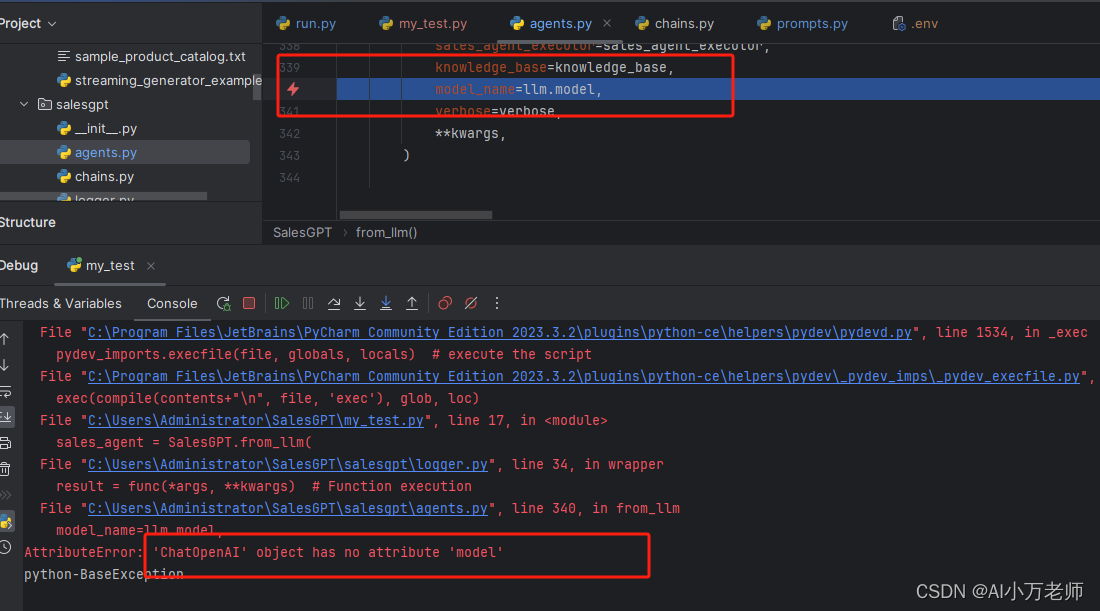
看报错位置和报错提示,大概能猜出来,由于我换了模型,ChatOpenAI这个模型缺少model这个参数,所以就报错了(ChatLiteLLM模型有这个参数)。因为我们之前研究过SalesGPT的构造方法:
def from_llm(cls, llm: ChatLiteLLM, verbose: bool = False, **kwargs) -> "SalesGPT":不难看出,这个model_name并非构造SalesGPT的必要参数,是放在kwargs里面的东西,所以干脆注销掉就好了。由于我是改的项目源代码,所以在这里要注释一下,免得以后忘了为啥要把这行代码注释掉。 我们注释掉之后再跑一下,我建议大家用pycharm的debug一步一步地跑,这样可以清晰地看到里面的运行过程、线程和参数:

OK,到这里,项目开始跑起来了,这里看到已经开始构造StageAnalyzerChain了,我们继续往下看看,可以看到历史记录是空的,我们和openai的交互也成功了,也正确输出了:

prompt提示词调整
虽然项目跑起来了,但是仔细检查里面的过程,还是有问题:
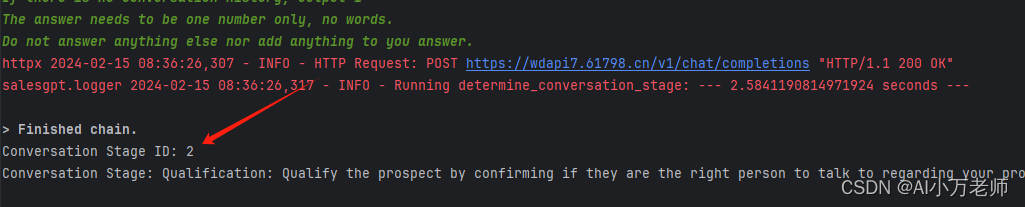
可以看到这里出了问题,我们第一次跑这个项目,之前是没有历史聊天记录的,但是在第一次做阶段判断的时候,直接stage分析的时候直接判定到了第二个阶段,这个是有问题的。解决方法有两个,一个是换更好用、逻辑推理能力更强的GPT-4模型,还有一个办法就是对项目自带的prompt提示词进行修改和优化如下:
Current Conversation stage is: {conversation_stage_id} check conversation history step by step,if converssation history is null,output 1. The answer needs to be one number only, no words. Do not answer anything else nor add anything to you answer.""" # If there is no conversation history, output 1
“If there is no conversation history, output 1”是原来项目里的提示词,感觉不太好用,我们用我自己写的提示词“check conversation history step by step,if converssation history is null,output 1.”,这里应用了提示词工程的小技巧(思维链),让大模型在检查这里的时候不要给我糊弄,好好看,我们再运行一下项目:

可以看到,我们换了提示词之后,大模型终于把这块整明白了,阶段输出也正确了。
不断向agent提问,理解整个业务逻辑 ,查看中间过程
我们下面可以不断地向用户提问,其实就是不断重复这个流程:
sales_agent.determine_conversation_stage()
sales_agent.step()
agent_output = sales_agent.conversation_history[-1]
human_input = input('say something')
sales_agent.human_step(human_input)先进行阶段判断,然后根据阶段判断agent先进行输出,然后用户再进行输出,你可以用pycharm的debug功能清晰看到中间过程:
输出结果和日志在console里看,线程和参数在threads&variables里看:

在这里点开,你可以看到你代码构造的实例和变量,里面的东西太多了,大家自己点进去看吧,有助于你里面代码背后的东西。
seed_agent()方法
我们之前已经介绍了SalesGPT最重要的from_llm()类方法,这个方法同时也是这个类的构造方法,我们继续来看一下我们demo用到的SalesGPT的其他方法,注意,这些方法都不是类方法,都是实例方法,他们都是我们在实例化获得了一个sales_agent之后调用的。第一个是seed_agent()方法:
@time_logger
def seed_agent(self):
# Step 1: seed the conversation
self.current_conversation_stage = self.retrieve_conversation_stage("1")
self.conversation_history = []这个方法的上面加了一个装饰器,用于计时的,代码里面的内容就是初始化一下,没啥好说的。
determine_conversation_stage()方法
调用类的实例属性stage_analyzer_chain来进行阶段判断,输入的参数有三个如下,这里要对内容做一些格式上的调整,函数的输出就是把类的conversation_stage_id,current_conversation_stage这个两个值属性进行了对应的修改:
@time_logger
def determine_conversation_stage(self):
self.conversation_stage_id = self.stage_analyzer_chain.run(
conversation_history="\n".join(self.conversation_history).rstrip("\n"),
conversation_stage_id=self.conversation_stage_id,
conversation_stages="\n".join(
[
str(key) + ": " + str(value)
for key, value in CONVERSATION_STAGES.items()
]
),
)
print(f"Conversation Stage ID: {self.conversation_stage_id}")
self.current_conversation_stage = self.retrieve_conversation_stage(
self.conversation_stage_id
)
print(f"Conversation Stage: {self.current_conversation_stage}")step()方法和_call()方法
step()方法里面做了一个简单判断,因为我们不需要stream的输出样式,所以就是去调用_call()方法,这个方法是一个类内部方法:
@time_logger
def step(self, stream: bool = False):
"""
Args:
stream (bool): whether or not return
streaming generator object to manipulate streaming chunks in downstream applications.
"""
if not stream:
self._call(inputs={})
else:
return self._streaming_generator()_call()方法:
def _call(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""Run one step of the sales agent."""
# override inputs temporarily
inputs = {
"input": "",
"conversation_stage": self.current_conversation_stage,
"conversation_history": "\n".join(self.conversation_history),
"salesperson_name": self.salesperson_name,
"salesperson_role": self.salesperson_role,
"company_name": self.company_name,
"company_business": self.company_business,
"company_values": self.company_values,
"conversation_purpose": self.conversation_purpose,
"conversation_type": self.conversation_type,
}
# Generate agent's utterance
if self.use_tools:
ai_message = self.sales_agent_executor.invoke(inputs)
output = ai_message["output"]
else:
ai_message = self.sales_conversation_utterance_chain.invoke(inputs)
output = ai_message["text"]
# Add agent's response to conversation history
agent_name = self.salesperson_name
output = agent_name + ": " + output
if "<END_OF_TURN>" not in output:
output += " <END_OF_TURN>"
self.conversation_history.append(output)
print(output.replace("<END_OF_TURN>", ""))
return ai_message注意,这里的input是空的:
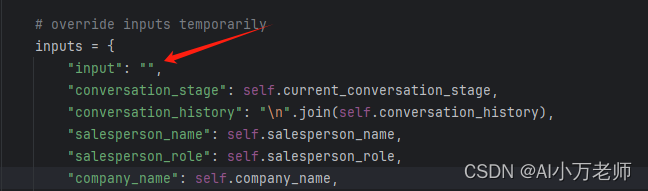
因为系统输出只依赖于现在对话处于哪个阶段,并不依赖于用户输入的具体内容!这里困扰了我好久,我当时一直和我自己之前写的agent做比较,我还纳闷呢,为啥这个agent输入没有用户的Input呢?现在我明白了,用户的输入就是用来帮助进行阶段判断的,系统的输出只依赖于现在处于哪个阶段。
继续往下看,如果使用了tools就用sales_agent_executor,否则就用sales_conversation_utterrance_chain,因此我们之前的demo运行都用的sales_conversation_utterrance_chain,下节课我们来用sales_agent_executor。
# Generate agent's utterance
if self.use_tools:
ai_message = self.sales_agent_executor.invoke(inputs)
output = ai_message["output"]
else:
ai_message = self.sales_conversation_utterance_chain.invoke(inputs)
output = ai_message["text"]最后要把大模型给的输出结果包装一下,放到conversation_history里,ai_message作为函数的返回结果:
# Add agent's response to conversation history
agent_name = self.salesperson_name
output = agent_name + ": " + output
if "<END_OF_TURN>" not in output:
output += " <END_OF_TURN>"
self.conversation_history.append(output)
print(output.replace("<END_OF_TURN>", ""))
return ai_messagehuman_step()
这个就更简单了,不说了。
def human_step(self, human_input):
# process human input
human_input = "User: " + human_input + " <END_OF_TURN>"
self.conversation_history.append(human_input)至此,我们就把如何把这个项目跑起来展示了一遍,我们对项目源码做了两处修改,大家注意要同样修改源码之后才能运行我们自己的代码,我贴一下整个my_test整体代码:
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from salesgpt.agents import SalesGPT
load_dotenv()
print(os.getenv("OPENAI_API_KEY"))
llm = ChatOpenAI(
temperature=0,
openai_api_key = os.getenv("OPENAI_API_KEY"),
base_url = os.getenv("OPENAI_BASE_URL")
)
sales_agent = SalesGPT.from_llm(
llm,
verbose=True,
use_tools=False,
salesperson_name="Ted Lasso",
salesperson_role="Sales Representative",
company_name="Sleep Haven",
company_business="""Sleep Haven
is a premium mattress company that provides
customers with the most comfortable and
supportive sleeping experience possible.
We offer a range of high-quality mattresses,
pillows, and bedding accessories
that are designed to meet the unique
needs of our customers.""",
)
sales_agent.seed_agent()
sales_agent.determine_conversation_stage()
sales_agent.step()
agent_output = sales_agent.conversation_history[-1]
assert agent_output is not None, "Agent output cannot be None."
assert isinstance(agent_output, str), "Agent output needs to be of type str"
assert len(agent_output) > 0, "Length of output needs to be greater than 0."
human_input = input('say something')
sales_agent.human_step(human_input)
sales_agent.determine_conversation_stage()
sales_agent.step()
agent_output = sales_agent.conversation_history[-1]
human_input = input('say something')
sales_agent.human_step(human_input)
sales_agent.determine_conversation_stage()
sales_agent.step()
agent_output = sales_agent.conversation_history[-1]