GPT推出了Fine-tune微调模型,让我们可以基于自己的数据,对GPT进行微调训练。这里不讲述概念,因为网上都是概念,这里直接上实操。
下面我们根据Openai官方文档,来做基于gpt-3.5-turbo进行微调训练
准备数据
数据格式
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}
格式化并验证数据
新建一个python脚本
# We start by importing the required packages
import json
import os
import tiktoken
import numpy as np
from collections import defaultdict
# Next, we specify the data path and open the JSONL file
data_path = "<YOUR_JSON_FILE_HERE>"
# Load dataset
with open(data_path) as f:
dataset = [json.loads(line) for line in f]
# We can inspect the data quickly by checking the number of examples and the first item
# Initial dataset stats
print("Num examples:", len(dataset))
print("First example:")
for message in dataset[0]["messages"]:
print(message)
# Now that we have a sense of the data, we need to go through all the different examples and check to make sure the formatting is correct and matches the Chat completions message structure
# Format error checks
format_errors = defaultdict(int)
for ex in dataset:
if not isinstance(ex, dict):
format_errors["data_type"] += 1
continue
messages = ex.get("messages", None)
if not messages:
format_errors["missing_messages_list"] += 1
continue
for message in messages:
if "role" not in message or "content" not in message:
format_errors["message_missing_key"] += 1
if any(k not in ("role", "content", "name") for k in message):
format_errors["message_unrecognized_key"] += 1
if message.get("role", None) not in ("system", "user", "assistant"):
format_errors["unrecognized_role"] += 1
content = message.get("content", None)
if not content or not isinstance(content, str):
format_errors["missing_content"] += 1
if not any(message.get("role", None) == "assistant" for message in messages):
format_errors["example_missing_assistant_message"] += 1
if format_errors:
print("Found errors:")
for k, v in format_errors.items():
print(f"{k}: {v}")
else:
print("No errors found")
# Beyond the structure of the message, we also need to ensure that the length does not exceed the 4096 token limit.
# Token counting functions
encoding = tiktoken.get_encoding("cl100k_base")
# not exact!
# simplified from https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
def num_tokens_from_messages(messages, tokens_per_message=3, tokens_per_name=1):
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3
return num_tokens
def num_assistant_tokens_from_messages(messages):
num_tokens = 0
for message in messages:
if message["role"] == "assistant":
num_tokens += len(encoding.encode(message["content"]))
return num_tokens
def print_distribution(values, name):
print(f"\n#### Distribution of {name}:")
print(f"min / max: {min(values)}, {max(values)}")
print(f"mean / median: {np.mean(values)}, {np.median(values)}")
print(f"p5 / p95: {np.quantile(values, 0.1)}, {np.quantile(values, 0.9)}")
# Last, we can look at the results of the different formatting operations before proceeding with creating a fine-tuning job:
# Warnings and tokens counts
n_missing_system = 0
n_missing_user = 0
n_messages = []
convo_lens = []
assistant_message_lens = []
for ex in dataset:
messages = ex["messages"]
if not any(message["role"] == "system" for message in messages):
n_missing_system += 1
if not any(message["role"] == "user" for message in messages):
n_missing_user += 1
n_messages.append(len(messages))
convo_lens.append(num_tokens_from_messages(messages))
assistant_message_lens.append(num_assistant_tokens_from_messages(messages))
print("Num examples missing system message:", n_missing_system)
print("Num examples missing user message:", n_missing_user)
print_distribution(n_messages, "num_messages_per_example")
print_distribution(convo_lens, "num_total_tokens_per_example")
print_distribution(assistant_message_lens, "num_assistant_tokens_per_example")
n_too_long = sum(l > 4096 for l in convo_lens)
print(f"\n{n_too_long} examples may be over the 4096 token limit, they will be truncated during fine-tuning")
# Pricing and default n_epochs estimate
MAX_TOKENS_PER_EXAMPLE = 4096
MIN_TARGET_EXAMPLES = 100
MAX_TARGET_EXAMPLES = 25000
TARGET_EPOCHS = 3
MIN_EPOCHS = 1
MAX_EPOCHS = 25
n_epochs = TARGET_EPOCHS
n_train_examples = len(dataset)
if n_train_examples * TARGET_EPOCHS < MIN_TARGET_EXAMPLES:
n_epochs = min(MAX_EPOCHS, MIN_TARGET_EXAMPLES // n_train_examples)
elif n_train_examples * TARGET_EPOCHS > MAX_TARGET_EXAMPLES:
n_epochs = max(MIN_EPOCHS, MAX_TARGET_EXAMPLES // n_train_examples)
n_billing_tokens_in_dataset = sum(min(MAX_TOKENS_PER_EXAMPLE, length) for length in convo_lens)
print(f"Dataset has ~{n_billing_tokens_in_dataset} tokens that will be charged for during training")
print(f"By default, you'll train for {n_epochs} epochs on this dataset")
print(f"By default, you'll be charged for ~{n_epochs * n_billing_tokens_in_dataset} tokens")
print("See pricing page to estimate total costs")
验证数据后,上传文件
openai.File.create(
file=open("mydata.jsonl", "rb"),
purpose='fine-tune'
)
使用 OpenAI SDK 开始微调工作:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.FineTuningJob.create(training_file="file-abc123", model="gpt-3.5-turbo")
使用微调模型
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
completion = openai.ChatCompletion.create(
model="ft:gpt-3.5-turbo:my-org:custom_suffix:id",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
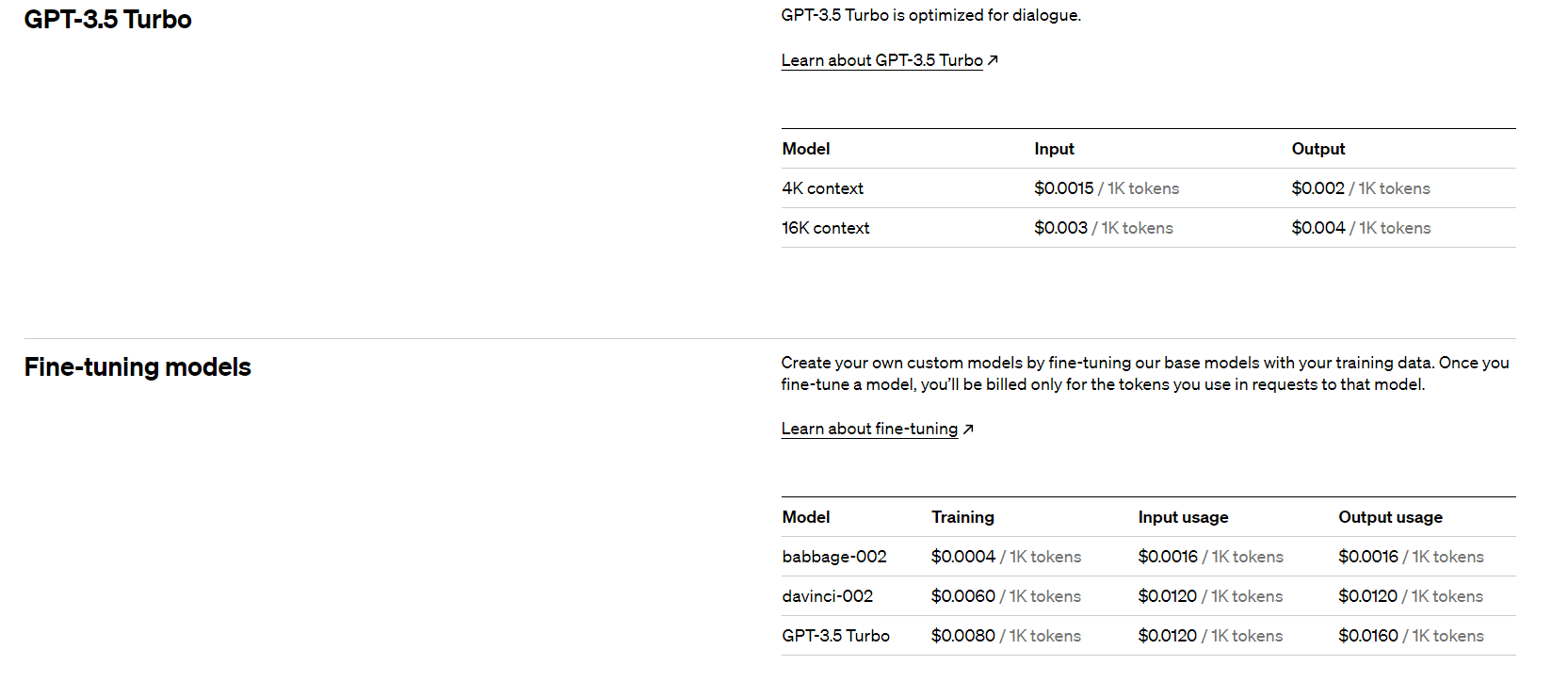
微调模型的价格
微调成本分为两部分:初始训练成本和使用成本:
培训:0.008 美元/1K tokens
使用输入:0.012 美元/1K tokens
使用输出:0.016 美元/1K tokens
例如,一个gpt-3.5-turbo包含 100,000 个tokens的训练文件并训练 3 个 epoch 的微调作业的预期成本为 2.40 美元。
程序源码
上面是根据openai官方做的,可能会遇到问题,我自己调试了一个,亲测可以用,可以私信我,获取调试过的源码。